epoll e io_uring explicados visualmente
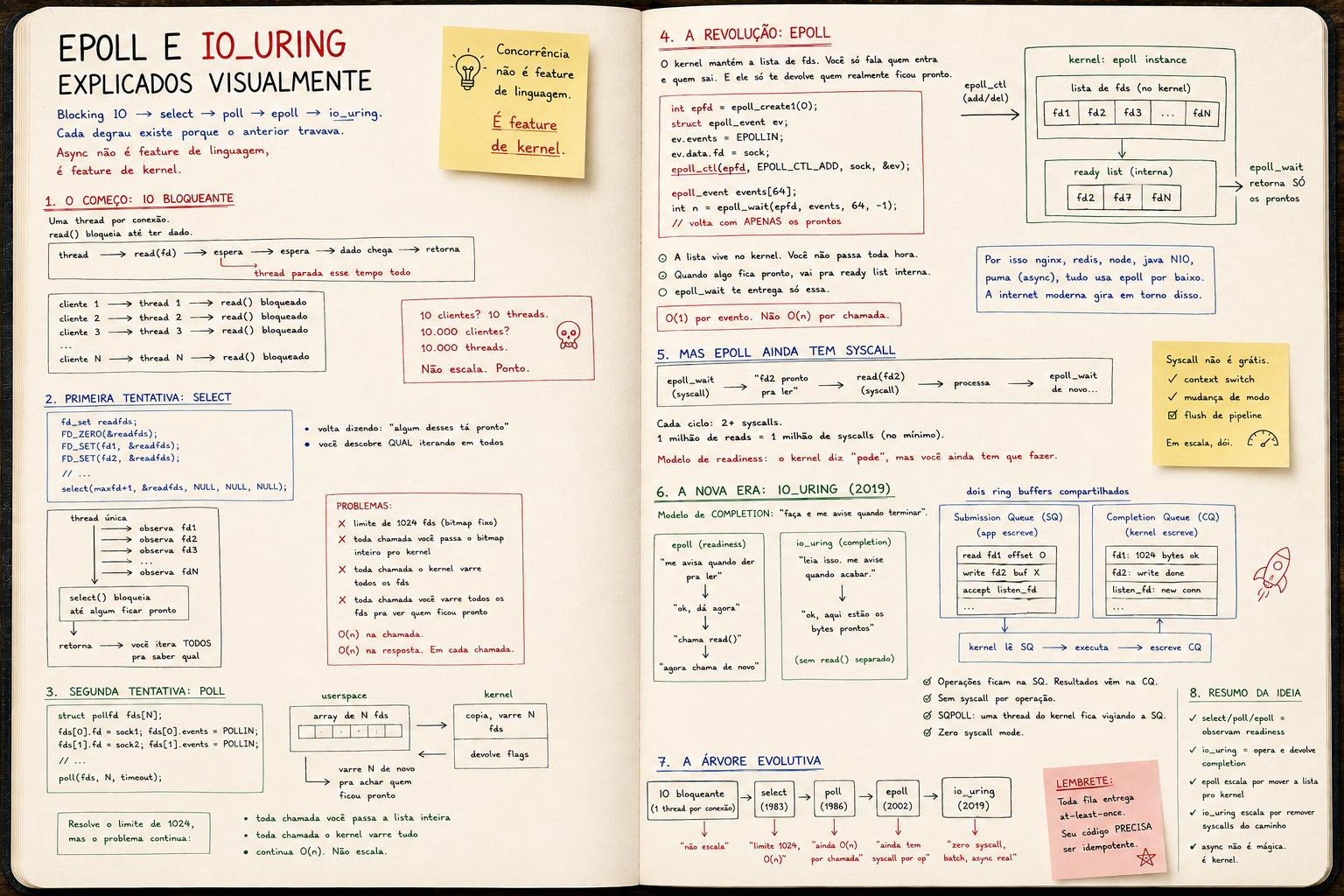
Blocking IO → select → poll → epoll → io_uring. Cada degrau existe porque o anterior travava. Async não é feature de linguagem, é feature de kernel.
epoll e io_uring explicados visualmente
Concorrência não é feature de linguagem.
É feature de kernel.
Async/await em JS, fibers em Ruby, goroutines em Go — tudo isso é fachada bonita por cima de duas ou três syscalls do Linux que ninguém quer estudar.
Hoje vamos estudar.
O começo: IO bloqueante
Antes de qualquer "magia", existia isso:
thread ──► read(fd) ──► espera ──► espera ──► dado chega ──► retorna
│
thread parada esse tempo todo
Uma thread por conexão. read() bloqueia até ter dado.
10 clientes? 10 threads. 10.000 clientes? 10.000 threads.
Cada thread come stack (~2MB por padrão no Linux), pressiona scheduler, polui cache de CPU.
cliente 1 ──► thread 1 ──► read() bloqueado
cliente 2 ──► thread 2 ──► read() bloqueado
cliente 3 ──► thread 3 ──► read() bloqueado
...
cliente N ──► thread N ──► read() bloqueado
Não escala. Ponto.
Primeira tentativa: select
A primeira ideia foi: e se uma thread só pudesse observar vários sockets?
select():
fd_set readfds;
FD_ZERO(&readfds);
FD_SET(fd1, &readfds);
FD_SET(fd2, &readfds);
// ...
select(maxfd+1, &readfds, NULL, NULL, NULL);
// volta dizendo: "algum desses tá pronto"
// você descobre QUAL iterando em todos
Visualmente:
thread única
│
├── observa fd1
├── observa fd2
├── observa fd3
└── observa fdN
│
select() bloqueia até algum ficar pronto
│
retorna ──► você itera TODOS pra saber qual
Problemas óbvios:
- limite de 1024 fds (bitmap fixo)
- toda chamada você passa o bitmap inteiro pro kernel
- toda chamada o kernel varre todos os fds
- toda chamada você varre todos os fds pra ver quem ficou pronto
O(n) na chamada. O(n) na resposta. Em cada chamada.
Com 10.000 conexões, é tragédia.
Segunda tentativa: poll
poll() resolveu o limite de 1024, usando array em vez de bitmap:
struct pollfd fds[N];
fds[0].fd = sock1; fds[0].events = POLLIN;
fds[1].fd = sock2; fds[1].events = POLLIN;
// ...
poll(fds, N, timeout);
Mas o problema fundamental continua: toda chamada você passa a lista inteira. Toda chamada o kernel varre tudo.
userspace kernel
┌──────────────────┐ ┌──────────────────┐
│ array de N fds │ ──────► │ copia, varre N │
│ │ ◄────── │ devolve flags │
└──────────────────┘ └──────────────────┘
varre N de novo
pra achar quem ficou pronto
Continua O(n). Continua não escalando.
A revolução: epoll
Em 2002 entrou no kernel a abstração que rege a internet moderna: epoll.
A ideia central:
O kernel mantém a lista de fds. Você só fala quem entra e quem sai. E ele só te devolve quem realmente ficou pronto.
Três syscalls:
int epfd = epoll_create1(0); // cria a "lista" no kernel
struct epoll_event ev;
ev.events = EPOLLIN;
ev.data.fd = sock;
epoll_ctl(epfd, EPOLL_CTL_ADD, sock, &ev); // adiciona um fd
epoll_event events[64];
int n = epoll_wait(epfd, events, 64, -1); // espera prontos
// volta com APENAS os prontos
Visualmente:
┌──────────────────────────┐
│ kernel: epoll instance │
│ ┌────────────────────┐ │
epoll_ctl ───► │ │ fd1 fd2 fd3 ... │ │ ◄── adiciona/remove
│ └────────────────────┘ │
│ │
│ ┌──── ready list ───┐ │
epoll_wait ──► │ │ fd2 fd7 │ │ ──► retorna SÓ os prontos
│ └───────────────────┘ │
└──────────────────────────┘
A lista de fds vive no kernel. Você não passa ela toda toda hora. Você só registra mudanças.
E quando algo fica pronto, vai pra ready list interna. epoll_wait te entrega só essa.
O(1) por evento. Não O(n) por chamada.
É por isso que nginx, redis, node, java NIO, puma (em modo IO async), tudo isso usa epoll por baixo. Toda a internet moderna gira em torno disso.
Mas epoll ainda tem syscall
Cada epoll_wait é uma syscall. Cada read() depois é outra syscall. Cada write() outra.
Syscall não é grátis. Tem context switch, mudança de modo de privilégio, flush de pipeline. Em servidor de milhões de req/s, o custo de syscall começa a aparecer no profile.
E mais: epoll te avisa que dá pra ler. Você ainda precisa chamar read depois. Isso é o que se chama de modelo de readiness:
1. epoll_wait ──► "fd2 tá pronto pra ler"
2. read(fd2) ──► tira os bytes
3. processa
4. epoll_wait de novo
Cada ciclo: 2+ syscalls. Sempre.
E se você quer fazer 1 milhão de reads, são 1 milhão de syscalls. No mínimo.
A nova era: io_uring
Em 2019, Jens Axboe lança io_uring. Não é epoll v2. É um modelo completamente diferente.
Em vez de readiness ("me avisa quando der pra ler"), io_uring usa completion ("faz isso e me avisa quando estiver feito"):
epoll (readiness): io_uring (completion):
"me avisa quando ler dar" "leia isso. me avisa quando acabar."
│ │
"ok, dá agora" "ok, aqui estão os bytes prontos"
│
"chama read()" (não precisa de read separado)
│
"agora chama de novo" (não precisa de syscall extra)
Como funciona: dois ring buffers compartilhados entre userspace e kernel:
┌─────────────────────── userspace ─────────────────────────┐
│ │
│ ┌─ Submission Queue (SQ) ─┐ ┌─ Completion Queue (CQ) ┐│
│ │ read fd1 offset 0 │ │ fd1: 1024 bytes ok ││
│ │ write fd2 buf X │ │ fd2: write done ││
│ │ accept listen_fd │ │ listen_fd: new conn ││
│ │ ... │ │ ... ││
│ └─────────────┬───────────┘ └────────────▲──────────┘│
│ │ │ │
└─────────────────┼──────────────────────────────┼───────────┘
│ mapeados em memória │
┌─────────────────▼──────────────────────────────┼───────────┐
│ kernel lê SQ kernel escreve CQ │
│ executa operações com resultados │
└────────────────────────────────────────────────────────────┘
Você escreve operações na SQ. O kernel lê delas, executa, e escreve resultados na CQ. Você lê da CQ.
Sem syscall por operação. As filas vivem em memória mapeada compartilhada.
E o melhor: zero syscall mode (SQPOLL). Uma thread do kernel fica acordada vigiando a SQ. Você só escreve no anel. O kernel pega sozinho.
modo normal: modo SQPOLL (zero syscall):
app escreve SQ app escreve SQ
│ │
io_uring_enter() ──► kernel thread do kernel já tá olhando
│ │
kernel processa processa sem ser chamada
│ │
escreve CQ escreve CQ
│ │
app lê CQ app lê CQ
Servidor de altíssimo desempenho consegue fazer milhares de IOs sem uma única syscall. Coisa que parecia impossível em Linux dez anos atrás.
A árvore evolutiva
IO bloqueante (1 thread por conexão)
│
│ "isso não escala"
▼
select() (1983)
│
│ "limite de 1024, O(n)"
▼
poll() (1986)
│
│ "ainda O(n) por chamada"
▼
epoll (2002)
│
│ "ainda tem syscall por op"
▼
io_uring (2019)
│
│ zero syscall, batch, async real
▼
(o futuro)
Cada salto resolveu o gargalo do anterior.
io_uring é tudo isso e o que mais?
io_uring não faz só read/write. Suporta:
- accept, connect, send, recv
- openat, close, statx
- fsync, fallocate
- splice, tee
- timeout, link de operações (uma depende da outra)
- até execução em batch encadeado
É praticamente uma VM de syscalls rodando no kernel.
Você pode dizer: "abre esse arquivo, lê 4KB, manda no socket, fecha". Tudo numa submissão. Sem voltar pra userspace no meio.
E o Ruby/Rails onde entra?
Aqui dói falar.
Ruby ainda está, em produção real, predominantemente em cima de epoll.
- Puma usa nio4r (Java NIO-style), que usa epoll
- Falcon (Async) usa o nio4r também, ou IO.select moderno
- Fibers Ruby 3.x melhoraram MUITO o jogo — finalmente dá pra fazer concorrência sem callback hell
Mas io_uring em Ruby? Mínimo. Existe gem rio_uring, alguns experimentos. Nada production-grade ainda.
E é tudo bem.
Porque a verdade desconfortável é: a maior parte das aplicações Ruby/Rails não está limitada por syscall overhead.
Está limitada por:
- query lenta no banco
- N+1
- GC pressure
- IO síncrono em thread bloqueante
- código mal estruturado
Trocar epoll por io_uring no seu Puma não te dá 2x throughput se sua request já gasta 300ms no Postgres.
Quando io_uring realmente importa
io_uring brilha quando:
- você está fazendo milhões de IOs/s
- a latência por syscall é mensurável no seu profile
- você tem workload de storage pesado (databases, filesystems)
- você tá escrevendo proxy/load balancer de altíssima carga
- você quer batchar operações fortemente
Quem usa hoje sério: ScyllaDB, novos engines de storage, alguns hyperscalers, alguns proxies (Cloudflare flertando), kernel bypass alternatives.
Quem não precisa: 99% das webapps Ruby/Rails/Django/Node CRUD da vida.
Senior vs junior
Junior: "Vou usar io_uring porque é mais novo e mais rápido."
Senior: "Onde meu request gasta tempo? Se for em DB, io_uring não muda nada. Se for em syscall, mostra o profile."
Trocar de tecnologia sem entender o gargalo é a ilusão que mais consome tempo de carreira.
A virada de chave
epoll te ensina:
- IO não é "esperar em sequência"
- uma thread pode observar milhares de coisas
- o kernel é seu parceiro de concorrência
io_uring te ensina:
- syscall em si é caro em escala
- submissão e completion podem ser separadas
- batch + memória compartilhada é o futuro
Os dois juntos te ensinam:
Concorrência não está no seu código. Está no kernel. Sua linguagem só está fingindo elegância em cima dele.
Conclusão
select → poll → epoll → io_uring.
Quatro décadas resumidas em "como uma thread vigia muita coisa sem custar caro".
Toda vez que alguém diz "essa linguagem é assíncrona", o que está dizendo de verdade é "essa linguagem chama epoll por baixo dos panos pra você".
Async não é feature de linguagem.
É feature de kernel.
E quem entende o kernel, entende async de verdade.
Os outros só decoram palavras-chave.