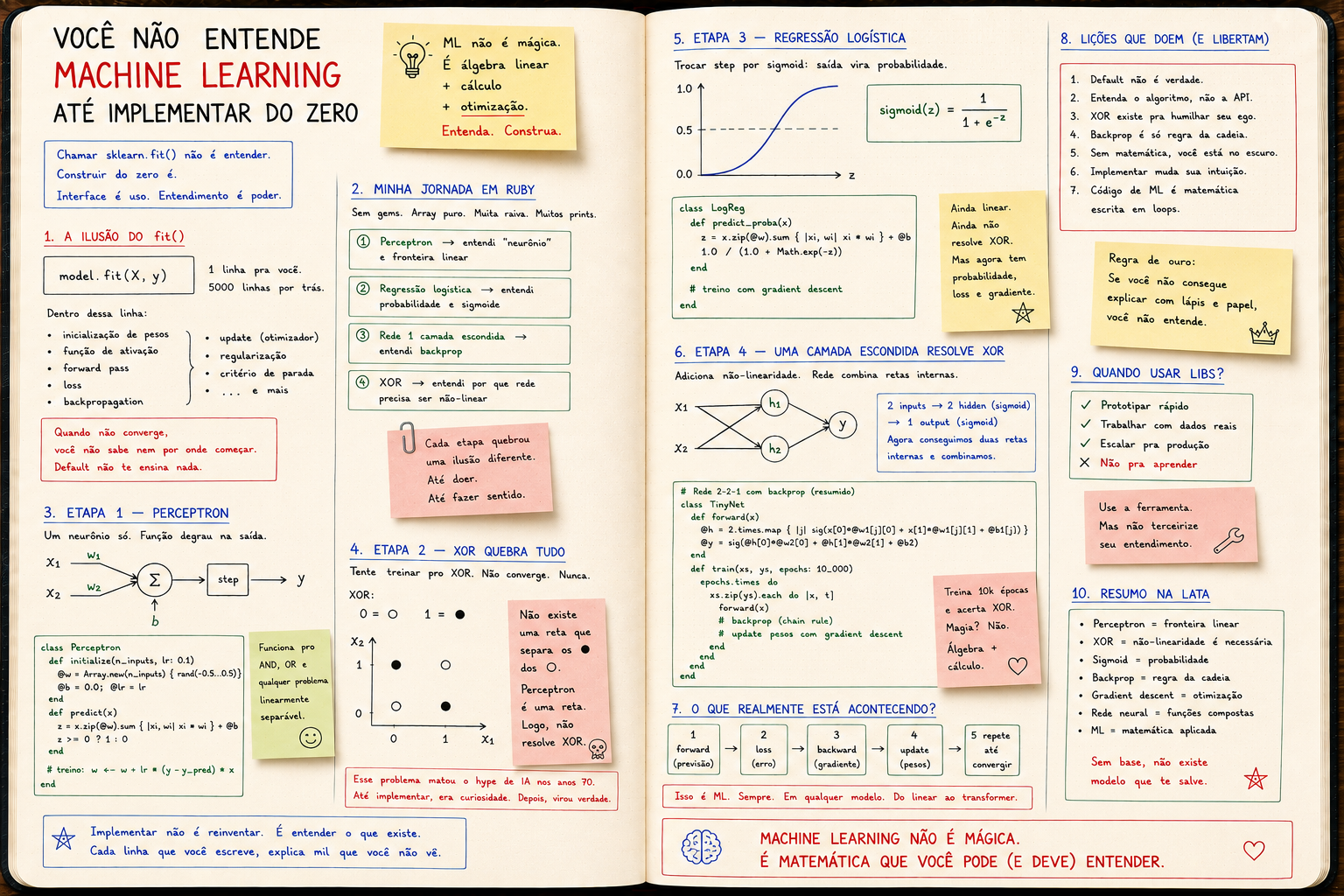
Você não entende Machine Learning até implementar do zero
Chamar sklearn.fit() não é entender. Construir perceptron, regressão logística e uma rede que resolve XOR em Ruby é. ML é álgebra e otimização — não mágica.
Você não entende Machine Learning até implementar do zero
Tem uma diferença gigante entre:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression().fit(X, y)
…e saber o que essas duas linhas estão fazendo.
A primeira é uso. A segunda é entendimento.
E a indústria inteira confunde as duas.
A ilusão do fit()
Importou. Chamou .fit(). Modelo treinou. 92% de acurácia.
Você "fez ML"?
Não. Você usou a interface.
┌──────────────────────────────────────┐
│ model.fit(X, y) │
│ │
│ o que você vê: 1 linha │
│ o que está dentro: 5000 linhas │
└──────────────────────────────────────┘
Dentro dessa linha tem:
- inicialização de pesos (e qual estratégia?)
- escolha de função de ativação
- forward pass
- cálculo de loss
- backpropagation
- update de pesos com algum otimizador
- critério de parada
- regularização
Você não escolheu nada disso. O default escolheu por você.
E aí vem o dia em que o modelo não converge. E você não sabe nem por onde começar.
Minha experiência: uma lib de ML em Ruby
Resolvi aprender ML do jeito que aprendi tudo em programação: escrevendo, não lendo.
Não me importava se ficaria lento. Não queria gem. Queria ver o sangue do algoritmo.
Em Ruby. Array puro. Sem NMatrix, sem Numo, sem nada.
O caminho foi este:
1. Perceptron → entendi "neurônio" e fronteira linear
2. Logistic regression → entendi probabilidade e sigmoide
3. Rede 1 camada → entendi backprop
4. XOR → entendi por que rede precisa ser não-linear
Cada etapa quebrou uma ilusão diferente.
Etapa 1 — Perceptron
O perceptron é um neurônio só.
x1 ──w1──┐
├──[ Σ ]──[ step ]── y
x2 ──w2──┘
↑
b
Pesos w, bias b, soma ponderada, função degrau na saída.
class Perceptron
def initialize(n_inputs, lr: 0.1)
@w = Array.new(n_inputs) { rand(-0.5..0.5) }
@b = 0.0
@lr = lr
end
def predict(x)
z = x.zip(@w).sum { |xi, wi| xi * wi } + @b
z >= 0 ? 1 : 0
end
def train(xs, ys, epochs: 20)
epochs.times do
xs.zip(ys).each do |x, y|
pred = predict(x)
error = y - pred
@w = @w.zip(x).map { |wi, xi| wi + @lr * error * xi }
@b += @lr * error
end
end
end
end
# AND lógico
xs = [[0,0],[0,1],[1,0],[1,1]]
ys = [0, 0, 0, 1]
p = Perceptron.new(2)
p.train(xs, ys)
xs.each { |x| puts "#{x.inspect} → #{p.predict(x)}" }
Funciona pro AND. Pro OR. Pra qualquer problema linearmente separável.
Aí veio o tapa.
Etapa 2 — XOR quebra tudo
Tentei treinar pro XOR:
xs = [[0,0],[0,1],[1,0],[1,1]]
ys = [0, 1, 1, 0]
Não converge. Nunca.
E aí entendi pela primeira vez o que separabilidade linear significa.
Plota XOR num plano:
x2
│
1 ● ○ ● = classe 1
│ ○ = classe 0
│
0 ○ ●
│
└────────── x1
0 1
Não tem reta que separa os ● dos ○. Não tem.
Perceptron é uma reta. Logo, perceptron não resolve XOR.
Esse foi o problema que matou o hype de IA nos anos 70.
E até eu implementar, era só uma curiosidade de livro.
Depois de implementar, virou conhecimento.
Etapa 3 — Regressão logística
Trocar step por sigmoid resolve algo importante: a saída vira probabilidade.
sigmoid(z) = 1 / (1 + e^-z)
1.0 │ ___________
│ __/
0.5 │ __/
│ __/
0.0 │__/
└──────────────────────── z
E como sigmoide é derivável, dá pra usar gradient descent de verdade.
class LogReg
def initialize(n_inputs, lr: 0.1)
@w = Array.new(n_inputs, 0.0)
@b = 0.0
@lr = lr
end
def sigmoid(z) = 1.0 / (1.0 + Math.exp(-z))
def predict_proba(x)
z = x.zip(@w).sum { |xi, wi| xi * wi } + @b
sigmoid(z)
end
def train(xs, ys, epochs: 1000)
n = xs.length.to_f
epochs.times do
dw = Array.new(@w.length, 0.0)
db = 0.0
xs.zip(ys).each do |x, y|
p = predict_proba(x)
err = p - y
@w.each_index { |i| dw[i] += err * x[i] }
db += err
end
@w.each_index { |i| @w[i] -= @lr * dw[i] / n }
@b -= @lr * db / n
end
end
end
Ainda linear. Ainda não resolve XOR. Mas agora tem probabilidade, gradient descent e loss diferenciável.
Falta uma coisa: profundidade.
Etapa 4 — Uma camada escondida resolve XOR
Adiciona uma camada de neurônios no meio:
x1 ─┐ ┌──[ h1 ]──┐
├────┤ ├──[ y ]
x2 ─┘ └──[ h2 ]──┘
Cada h é uma transformação não-linear da entrada. A saída combina os h.
Agora a rede consegue traçar duas retas internamente e combiná-las. XOR vira separável.
class TinyNet
# 2 inputs → 2 hidden (sigmoid) → 1 output (sigmoid)
def initialize(lr: 0.5)
@w1 = Array.new(2) { Array.new(2) { rand(-1.0..1.0) } } # 2x2
@b1 = Array.new(2, 0.0)
@w2 = Array.new(2) { rand(-1.0..1.0) } # 2
@b2 = 0.0
@lr = lr
end
def sig(z) = 1.0 / (1.0 + Math.exp(-z))
def dsig(s) = s * (1 - s)
def forward(x)
@h = Array.new(2) do |j|
sig(x[0] * @w1[j][0] + x[1] * @w1[j][1] + @b1[j])
end
@y = sig(@h[0] * @w2[0] + @h[1] * @w2[1] + @b2)
end
def train(xs, ys, epochs: 10_000)
epochs.times do
xs.zip(ys).each do |x, target|
# forward
out = forward(x)
# backward (chain rule)
d_out = (out - target) * dsig(out)
d_h = Array.new(2) { |j| d_out * @w2[j] * dsig(@h[j]) }
# updates
2.times { |j| @w2[j] -= @lr * d_out * @h[j] }
@b2 -= @lr * d_out
2.times do |j|
@w1[j][0] -= @lr * d_h[j] * x[0]
@w1[j][1] -= @lr * d_h[j] * x[1]
@b1[j] -= @lr * d_h[j]
end
end
end
end
end
xs = [[0,0],[0,1],[1,0],[1,1]]
ys = [0, 1, 1, 0]
net = TinyNet.new
net.train(xs, ys)
xs.each { |x| puts "#{x.inspect} → #{net.forward(x).round(3)}" }
Saída esperada:
[0, 0] → 0.04
[0, 1] → 0.96
[1, 0] → 0.96
[1, 1] → 0.05
Resolveu XOR. Em Ruby. Em 60 linhas. Sem gem nenhuma.
E só ali eu entendi backprop. Porque escrevi a regra da cadeia na mão.
O que fit() esconde
Olha tudo o que apareceu nesse exercício:
┌─ forward pass ─────────────────────────┐
│ composição de funções não-lineares │
└────────────────────────────────────────┘
┌─ loss ─────────────────────────────────┐
│ como mede o erro │
└────────────────────────────────────────┘
┌─ backprop ─────────────────────────────┐
│ regra da cadeia em camadas │
└────────────────────────────────────────┘
┌─ weight init ──────────────────────────┐
│ zero quebra. random pequeno funciona │
└────────────────────────────────────────┘
┌─ ativação ─────────────────────────────┐
│ step, sigmoid, tanh, ReLU… │
│ cada uma muda o que a rede consegue │
└────────────────────────────────────────┘
┌─ learning rate ────────────────────────┐
│ α grande explode, α pequeno trava │
└────────────────────────────────────────┘
Tudo isso some atrás de uma linha de sklearn.
Você nunca vai entender ML olhando essa linha.
Senior vs junior
- júnior importa um modelo, ajusta hiperparâmetro até a acurácia subir, e vai pra próxima task
- sênior sabe, pra cada linha de
fit(), qual operação está acontecendo e por quê
O júnior trata o modelo como caixa preta.
O sênior trata como álgebra com loop.
Diferença de salário e diferença de problema que cada um consegue resolver.
Por que isso muda tudo
Quando você implementa:
- entende por que normalizar dados importa (gradiente explode senão)
- entende por que inicialização importa (zero faz toda neurônio aprender igual)
- entende por que ReLU vingou (sigmoide satura, gradiente some)
- entende por que profundidade ajuda (mais composição = mais expressividade)
- entende por que rede grande precisa de muito dado (mais parâmetro = mais grau de liberdade)
Nada disso entra na cabeça lendo blog post.
Entra escrevendo o código.
Conclusão
Machine Learning não é mágica.
É álgebra linear, cálculo e otimização — orquestrados num loop.
E você só vê isso quando escreve o loop com as próprias mãos.
sklearn, PyTorch, TensorFlow são ferramentas excelentes — depois que você entende.
Antes, são camadas que escondem o que você precisava aprender.
Se você nunca implementou um perceptron, uma regressão logística e uma rede com uma camada escondida, você não sabe ML.
Você sabe a API.
E API muda. Fundamento, não.